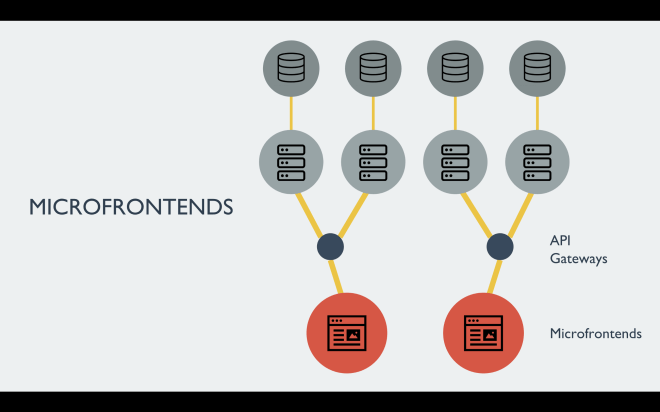
Following the previous posts on micro-frontends (1 and 2), it’s time to talk about how to orchestrate micro-frontends.
First of all and foremost, there are 2 schools of thoughts about how a micro-frontend should look like, as explained in the previous article where I was explained different implementations of micro-frontends, there are implementations where a micro-frontend correspond to an area of the user interface, others where the micro-frontend is a SPA or a single page.
When we consider the micro-frontends implementation based on different logical areas of the application (like a header, a footer, a payment form and so on) we would face different challenges like:
Which team would assemble the aggregated view?
How can we avoid external dependencies in every team?
Which team is accountable for an issue in the aggregated view?
How do we ensure that a specific area of the application is not tightly coupled with the parent container?
How can we be sure there aren’t conflicts between dependencies?
Are we assembling at runtime or compile time?
If we decide to create the page at runtime time, is our application servers layer scalable?
Is the content cachable and for how long?
How do we ensure the development flow is not impacted by distributed teams?And many other questions (technical and organisational) that could make our life way more complicated than how it could be.
Interestingly enough, this approach didn’t provide the expected benefits for Spotify working at scale and they reverted back to a more “classic” architecture based on SPA.
For the benefits of this post, let’s define our micro-frontends as SPA or single pages with a generation made at compile time in order to avoid any possible surprise happening at the composition layer.
Anyway, there are some challenges to face also with this approach, probably the main one is understanding how we want to orchestrate our micro-frontends and it is the focus of this post.
The orchestrator layer could be either on the client-side, server-side or edge-side; the solution depends on how “smart” the orchestrator layer should look like for our applications.
Server-side or edge-side orchestrator
A server-side or edge-side orchestrator would mean that for any deep-link or organic traffic hitting our domain has to be analysed by an application server or an edge solution (lambda@edge for instance), in both cases we need to maintain a map of URLs that correspond to static HTML files (aka micro-frontends).
For instance, if a user logs out from our application we should probably unload the authenticated micro-frontend and load the sign in/sign up micro-frontend, therefore the application server or the code running on the edge should know which HTML file to serve for every URL or group of URLs in the case we are going to work with SPAs.
This technique could work without any problem considering we can change quickly the micro-frontends map directly on the server without any impact on the client-side, but presents some potential challenges, like finding the best way to share data across micro-frontends considering there are some limits of storage inside the browser and doing too many roundtrips to the servers is not ideal in particular for slow connections.
Another challenge would be finding a solution for initialising the application, considering with micro-frontends we split the monolith into multiple subdomains, are we going to initialise the application every time a new micro-frontend is loaded? Are we going to use Server Side Rendering storing the configuration inside the HTML? How do we communicate between micro-frontends? How do we scale our application servers when there is bursty traffic?
Those are some of the challenges for implementing a server-side or edge-side orchestrator.
Client-side orchestrator
Another possible approach could be to create a client-side orchestrator responsible for:
— initialise the application
— sharing the application’s configurations to all the micro-frontends
— load/unload a micro-frontend based on the user’s state
— routing between micro-frontends
— exposing an API for interacting between a micro-frontend and the client-side orchestrator
One of the PROs of this solution is that you have more control over the application initialisation.
If well designed, the client-side orchestrator doesn’t need to change too often, therefore, will be fairly stable.
It provides additional functionality that could be used by various micro-frontends but it’s not domain specific, it’s also a great solution when our aim is to abstract our micro-frontends from the platform they are running on (browser instead of mobile devices or smart TVs).
The main CON is the initial investment in identifying which feature should be handled by this orchestrator because the risk of a big ball of mud is behind the corner, a bug on this layer could blow up the entire application and the implementation of new features, if not well co-ordinated, could slow down other teams creating a cross-team dependency.
In DAZN we opted for a client-side orchestrator that we called bootstrap.
Bootstrap has all the responsibilities listed above plus an additional one related to our use case, in fact, bootstrap is abstracting the I/O APIs of the platform where the application is running on, in this way each micro-frontend is completed unaware in which platform is loaded.
With this technique, we can re-use a micro-frontend across multiple smart TVs, consoles or set-top boxes without the need to rewrite specific device’s implementations, unless the implementation has memory leaks or performance issues.
Bootstrap is served every time a user types our domain in the browser or opens the application on a smart TV, it’s always present and never unloaded for the entire duration of the user session.

Let’s try to expand further about the bootstrap in order to understand the main ideas behind it:
Initialise the application
Bootstrap should be responsible to set the application context, first of all understanding if the user is authenticated or not and based on the application initialisation we can load the correct micro-frontend.
Any other meaningful information your application needs for setting the context for the entire application should be managed at this stage.
It could be a static configuration (JSON) or dynamic one where an API needs to be consumed, either way, having an external configuration for our frontend allow us to change some behaviours of our system without the need of bootstrap releases.
For instance, a configuration could provide valuable information for the application lifecycle like features toggles, localised labels for the user interface and so on.
Micro-frontends routing
Bootstrap is definitely responsible for routing between micro-frontends, in our implementation, we have 2 routing spread between bootstrap and every micro-frontend.
Bootstrap doesn’t have the entire URLs map of our applications, instead, it loads in memory a map of which micro-frontend should be loaded based on the user status and the URL requested via user’s interactions or deep link.
Those two dimensions allow us to load the correct micro-frontend and leave to the micro-frontend code handling the URLs to manage inside different views that compose it.
A rule of thumb here is to assign a specific second level path for a micro-frontend so it would be easier to address the scope of a micro-frontend, for instance, the authentication micro-frontend should be loaded when the user types mydomain.com/account/*, instead, the micro-frontend for the help pages should be loaded when the user clicks on a link like mydomain.com/support/* and so on.
Inside every single micro-frontend, we can then decide to have additional paths like mydomain.com/support/help-page-A or mydomain.com/support/help-page-B, in this way the domain knowledge would be retained inside the micro-frontend without spreading it across multiple parts of the application.
The main takeaway here is that we have two types of routing in a micro-frontend application with a client-side orchestrator, a global one at bootstrap level and a local one inside the micro-frontend.
Micro-frontends lifecycle
As we mentioned before, each micro-frontends should be loaded via the boostrap, but how?
Single-spa, for instance, uses a javascript file as an entry point for mounting a new micro-frontend.
In DAZN, we took a different approach because using just a javascript file for loading a micro-fronted would have precluded the possibility to use server-side rendering at compile time that was an interesting option for us to provide faster feedback to our user meanwhile they were transitioning from a micro-frontend to another one.

Considering an HTML file is basically an XML file with a specific schema, bootstrap can load and parse the file appending inside itself all the relevant nodes for loading a micro-frontend using DOMParser, a standard interface for parsing XML or HTML strings.
Anything inside the body or head tags could be appended inside bootstrap’s DOM tree.
Potentially, we can also decide to define specific attributes for all the tags we need to append in order to have a quick way of selecting them.
Anyway, the overall idea is parsing an HTML file and appending inside bootstrap what is needed for loading the micro-frontend, therefore any external dependency (like a JavaScript or CSS file) present in the micro-frontend HTML file will be appended and therefore loaded by the browser.
A huge benefit of this neat approach is that it’s not opinionated, anyone can start working on a new micro-frontend without learning the way we decided to deal with micro-frontends because at the end, as long the micro-frontend output results in the Frontend holy trinity: an HTML, a JavaScript and a CSS files.
I captured a video throttling the connection in order to show how the bootstrap appends the DOM elements inside itself, as you will see there are 4 phases:
— identifying the micro-frontend to load,
— load the HTML of the micro-frontend,
— parse it,
—append the relevant tags for displaying the micro-frontend in the page.
It’s a very simple but effective mechanism!
An additional feature added to each micro-frontend is the possibility to perform some actions after and before are mounted or unmounted, in this way the micro-frontend can do any logic for cleaning up any object appended to the window object or any other logic to run in one of the 4 lifecycle’s methods mentioned before.
Bootstrap is responsible to trigger the micro-frontend lifecycle methods and clean the memory before loading the next micro-frontend, this action ensures no conflicts are happening in different or the same versions of a library used by different micro-frontends.
Bootstrap memory and dependencies management
It’s time to deep dive into the micro-frontends memory management, considering bootstrap is loading one micro-frontend per time, as explained in the previous post, and each micro-frontend is not sharing any library or dependency with another micro-frontend, we could end up in a situation where a micro-frontend is loading React v.15 and the next one React v.16.
At the same time, we want to have the freedom to pick any technology and library version inside every micro-frontend because the development team that retain the business and technical knowledge should make the best implementation choice available instead of having constant trade-offs across the entire application as usually happens when we work with a Single Page Application.
At this stage, I believe is very easy to guess the challenge we are facing because any library or framework used by a micro-frontend will append objects on the global window one and in Javascript we cannot directly control the garbage collector but we can facilitate the disposal of an element removing all the references and instances of a given object.
For achieving this goal, an additional bootstrap responsibility is keeping track of any object that is appended to the window object by any micro-frontend and cleaning the window object after unloading the micro-frontend but before a new one is loaded (the joy of metaprogramming in JavaScript 🎉).
Bootstrap takes a snapshot of all the keys appended to the window object and removes them before loading a new micro-frontend, in this way we keep track of what should be removed without duplicating any objects in memory and with a simple iteration of this array we delete any objects used by the unloaded micro-frontends inside the window object.
APIs layer for communicating between bootstrap and a micro-frontend
The last bit worth mentioning is the APIs layer exposed by the bootstrap via the window object.
If you asked yourself how we share data and communicate between micro-frontends, bootstrap is the answer!
Remember that our implementation is based on the assumption we always load one micro-frontend per time and we slice a micro-frontend based on a subdomain of our application, you will soon realise that the data shared across micro-frontends are not happening too often if you work well in the initial session where you define all your subdomains.
Sharing data between micro-frontends is pretty easy, bootstrap shares some APIs for storing and retrieving information accessible by any micro-frontends, it’s up to you deciding which storage is more convenient for your implementation and what kind of limits you wanna add to the objects to store locally.
Considering the bootstrap is a tiny layer written in vanilla JavaScript in between a platform and a micro-frontends and it’s initialising the application, we need also to expose an API layer for abstracting the I/O layer for storing or retrieving information from and to a micro-frontend.
Working with multiple devices require to have different APIs for storing and retrieving files because web storage APIs are not always consistent across all those platforms.
Another important part to highlight is the configuration retrieved from a static JSON file or an API that usually is shared with all the micro-frontends to understand the context where they are running (for instance sharing particular configuration based on the country or languages).
The most important thing when we design the APIs exposed by the bootstrap is trying to be forward-thinking because the bootstrap should be a layer that doesn’t change at every release otherwise you could break some contracts with micro-frontends and coupling the micro-frontends to bootstrap functionalities could jeopardise all the great work done splitting up your business domain in multiple subdomains.
Summary
During this post, we have explored the possibilities for orchestrating micro-frontends, we deep dive into the client-side orchestrator that in DAZN is called bootstrap, in particular, we have seen the benefits and the challenges of this approach and how we have managed to solve them.
In particular, we saw the bootstrap has 3 main responsibilities:
— routing between micro-frontends (load, unload and lifecycle methods)
— initialise the application
— exposing an APIs layer for micro-frontends communication and web storage
One of the questions I received very often after sharing those posts is if and when the bootstrap will be open-sourced, the answer is that we are thinking about that but we cannot commit to a timeline at the moment (that’s also the reason why I didn’t share code in this post, sorry again 🙏).
I really hope you are getting a clearer idea of how to structure your next micro-frontends project if not feel free to reach out, so I can have food for thoughts for the next post! ✌️