In the past 5 years, I had the opportunity to work in an OTT platform called DAZN that streams live and on-demand sports events across the globe.
During this journey, we had to overcome several challenges considering we were (and still are) pioneers of live video streaming. After the first release, I realized in order to scale the organization we had to rethink our platform to allow us scaling not only from a technology point of view but also from a people perspective.
For achieving this, we had to review several approaches and common practices for scaling our company and onboard more and more people working on the same project.
Our answer was embracing a new frontend architecture called Micro-Frontends that in combination with Microservices help us to scale our teams, creating independent artefacts that are mapped with our business domains. Micro-Frontends bring a new approach for scaling frontend projects, decentralizing the decision making and stopping the one-size-fits-all approaches very well known by the frontend community.
I decided to gather my experience building our Micro-Frontends architecture and share it into the pages of a book.
For more information, I suggest visiting the book website where you can also subscribe to the updates. I’ll keep you informed on the next chapters, new content released online, events where I’ll talk about Micro-Frontends and more.
The early release allows you to share your feedback with me, shaping the content inside the book and having a voice during the writing process, don’t miss this opportunity, WE can do an awesome job TOGETHER.
In the past year (2019) I spent a lot of time talking, writing, podcasting and just chatting with people about micro-frontends.
I’m truly passionate about the topic, mainly because it’s still an unexplored land where challenges arise every single day.
During all my talks, workshops and webinars I was building step by step a mental model that allowed me to simplify my thoughts for making them approachable by people listening to me or reading my contents.
I’m sure there is still a lot of work to do but from the feedback I received so far, I was able to explain in a reasonable way what I had in my mind.
Recently I had the pleasure to do a 2h workshop in Bergen (Norway) about this topic and during my presentation (literally on the stage) I realized that I was very close to simplify even further the decisions process for embracing a micro-frontends architecture.
In JavaScriptland we are used to choosing a framework and getting along with that for the entire lifecycle of a project, sometimes we change it in favor of another one but many times we stick with it for many months/years till the end of life for a specific project.
Every time we use a JavaScript framework, someone else made architectural decisions that we live with (or trying to) and we focus on what matters the most from a business point of view: the features of an application.
This doesn’t mean we have an easy challenge in front of us at all, we still have an essential part of this “game” taking the right design decisions for delivering the project, but first, we need to focus on having a solid base that allows us to build on top of it, aka the architecture.
“Software architecture is those decisions which are both important and hard to change”
Based on this definition, focusing on the key things, even better, the most important decisions for defining a micro-frontends architecture I came up with 4 pillars we have to decide upfront when we start architecting a micro-frontends project.
Those pillars can be summarized in:
1. Definition
2. Composition
3. Route
4. Communication
Each of them plays a fundamental role in the good outcome of a micro-frontends project.
After taking those 4 decisions there will be many others to take along the journey but with those cornerstones, we should be able to cascade vast majority of the other decisions without any need of evaluating again our architecture.
Bear in mind that those decisions could change over the lifecycle of a project but changing them will require a considerable development effort in order to achieve a coherent project’s architecture.
Defining Micro-Frontends
The first decision to take is how we identify a micro-frontend, is it a part of a view (horizontal split) or the entire view (vertical split)?
Splitting horizontally would mean identifying micro-frontends inside the same view, therefore multiple teams are taking care of the page composition coordinating themselves for the final result presented to a user.
Splitting vertically, instead, would assign a specific view, or group of views, to a team allowing that team mastering a specific area of the application.
In general, deciding to approach a micro-frontends project with a vertical slicing will simplify many decisions to take further down the line, because it’s closer the way a frontend developer is used to work so many practices can be easily applied to this approach.
Also, the coordination between teams should be easier considering each team is owning a vertical slice of the application and not multiple parts spread across the application.
There are additional challenges when we decide to go with the horizontal split, anyway I described more in-depth how to identify micro-frontends in another post available on this website.
Micro-Frontends Composition
The second decision is understanding where we want to compose micro-frontends, here we have 3 options to choose from:
client-side composition
edge-side composition
server-side composition
Client-side means implementing techniques like an App Shell loading single page applications, for instance, check out Single-SPA project, with iframes like Luigi framework or via a library using client-side transclusion technique.
Implementing over the edge would mean using CDNs capabilities like Edge-side includes (not always available in all the CDN providers or not fully implemented) or via computation happening on/near the edge (bear in mind there are restrictions in how much logic we could run with a solution like lambda@edge for instance).
Finally, on the server-side, there are plenty of frameworks like Ara Framework, Open Components, Piral or Tailor.js and many others.
When we decide to go with a vertical split we should aim for a client-side composition using Single-SPA or similar mechanisms like we do in DAZN.
Instead, when we decide to identify our micro-frontends as a single part of a view we have all the options available (client-side, edge-side and server-side).
Micro-Frontends Routing
After defining our micro-frontends composition strategy we need to decide how we want to route our views.
This time the decision is not mutually exclusive, we can decide to route client-side and adding logic on the edge or having the routing logic on the client or server only.
In this case, my suggestion is to be coherent with the composition part if you have decided to go with a client-side composition, use the app shell for mapping the routing logic, if you have chosen the server-side composition, use the webserver for managing the routing logic.
In the case we decided to go with the edge-side composition we will rely on the URL associated with a page.
In the following diagram, you can easily discover the different routing possibilities associated with a composition technique.
The final decision is finding a good way of communicating between micro-frontends bearing in mind that are independent units that should be completely decoupled between each other.
When we decide to have multiple micro-frontends on the same page we need to decide how (and if) a micro-frontend should notify when an event or a user interaction happens for coordinating changes in other micro-frontends.
In this case, we could use custom events or an event emitter library (there are many available) so our micro-frontends just emit/dispatch an event and who is listening reacts to that specific event.
However, either we identify multiple micro-frontends per page or we consider a micro-frontend an entire view, we need to decide how a view would exchange data with another view.
We can decide to use a web-storage solution (local and/or session storage) where every time a new view is loaded looks inside the web-storage to find the information needed or a URL routing where the application request to the backend the user state as displayed in the following diagram.
As we have seen, there are some decisions to make when we want to approach a micro-frontends architecture, those will shape the other challenges will be faced alongside a micro-frontends project like how to create a seamless user experience, how to define our CI/CD pipelines, how to optimize our micro-frontends reducing our JavaScript bundles and so on.
However, those 4 decisions made upfront will provide a strong guideline for facing all the other challenges and restrict the number of options to choose from.
Last but not least…
During my last keynote at JS-Poland I introduced this decisions framework for the first time, you can find the slides here (hopefully the recording soon!) with some additional details.
I’d really like to hear your feedback about this decisions framework.
If you feel it may help in your current or future projects if you think something is missing, if you think you have a better way to summarize a complex topic like this one, please leave a comment, I’m eager to read your point of view.
I’ve always spent a lot of time reading, attending conferences, researching different topics and those learnings really helped me shape my career, one of them is definitely Domain Driven Design (DDD).
Let’s take a step back first, why am I talking about DDD?
One thing that always puzzled me in this industry is the lack of learnings from different technology communities, for instance, we can find quite a lot food for thoughts when we examine the principles behind microservices more than focusing on the bare implementation.
On the backend side, there are often practices, methodologies, more in general ideas, that are totally applicable on the frontend too, but often we don’t think how to do it.
Often just taking a step back, understanding why someone implemented a pattern over another, allows us to open up a world of opportunities that we would never think about because “it’s not the standard way to do things”.
Contaminations from different industries or technologies allow us to see the world from a different perspective, creating new possibilities not explored enough (or at all sometimes), giving us the possibility to apply concepts and mental model to our day to day work.
DDD key concepts
Ok, now we can explain why DDD is mentioned in a post where I talk about micro-frontends.
DDD brings on the table some of the key concepts for defining a micro-frontends because it helps our organisation to align the business with the tech side, unifying de facto 2 main areas of our companies: product and tech.
DDD starts with the idea of identifying parts of our application that represents a subdomain of the final application.
Usually, an application is focused on a core domain, for instance, Netflix core domain is streaming movies anywhere at any time, considering the domain is usually a complex proposition, DDD suggests to split the domain into multiple subdomains allowing a company to understand how to structure the company as well as the project.
Some examples of subdomains could be the authentication, customer support inventory management and so on.
Subdomains are divided into 3 categories:
. Core Subdomains: those are the main reason why an application should exist, core subdomains should be treated as a premium citizen in our organizations because they are the ones that deliver values above anything else . Supporting Subdomains: subdomains related to the core ones but not key differentiators, those subdomains could support the core subdomains but at the same time are not essential for delivering the real value to our users . Generic Subdomains: those are needed subdomains used for completing the platform and often the companies decide to go with off the shelf software because not strictly related to their domain, for instance, authentication or payments management, more in general anything that is not related to our code business
Inside each subdomain, tech and product teams should identify a ubiquitous language, or rather a way where business meets tech using the same language for identifying functionalities, objects but more, in general, the domain model.
Think about it, how often we speak with a product owner that defines part of an application in a completely different way from the techies!
Ubiquitous language is not a static language, should evolve with the business and the applications running alongside it.
In this way, we would be able to define a domain-model similar to what we discuss day to day with the domain experts, constantly up-to-date.
Let’s take Netflix for instance, I think we are all familiar with this famous streaming platform, a subdomain of Netflix might be the catalogue, inside it we can identify multiple areas with specific functionalities, those could be directly connected to backend APIs related to a subset of the entire application.
In Netflix case, they are using Backend For Frontend pattern (BFF) nevertheless the principles remain the same.
Netflix web platform
In this screenshot, we can identify some components, those might be linked to some microservices like the personalisation service, the catalogue per country, the most popular contents and so on.
Despite the technical integration that could be via backend for frontend, GraphQL, Server Side Rendering and so on, the most important thing to understand is that those areas are all linked to the same subdomain.
Therefore those microservices, as well as the frontend, should be encapsulated in a unique subdomain with its own ubiquitous language.
Following just an example to understand what a subdomain should contain:
An example of subdomain based on the Netflix platform
This is a fundamental step for identifying how to “slice” our application, understanding that the frontend is part of the subdomain allows us to think holistically about our web application.
If we then extend the concept to the infrastructure too, we finally see all the components for developing a subdomain in the hands of a team that can own Frontend, Backend and Infrastructure end to end without too many external dependencies.
Up to now, DDD was applied to the backend layer but not very often to the frontend as well, extending these concepts to the frontend allow us to easily identify our micro-frontends.
I’d like to highlight another important concept, a subdomain cannot (and shouldn’t) be recognised as a component in a page, it’s true that in each UI we can find links or graphical elements related to different subdomains but at the same time we need to understand that they are not standalone identifying a subdomain and they need to have teams owning a subdomain end to end as we are going to see in the next few paragraphs.
Identifying a micro-frontends bounded context
Following the DDD principles, identifying a micro-frontend becomes quite trivial.
Usually, there are 2 main scenarios to deal with on a day to day based: greenfield projects, usually very exciting for any developer but also more complicated because we don’t have real information about our user base and how they would consume our content; legacy projects, where we have a tons of information (if we have diligently tracked our users behaviours using Google Analytics or similar tools) and therefore it’s easier to rationalise a logical identification of bounded context across the entire platform following our users’ behaviours
Having data to consult is one of the best situations we can aim for, understanding the users’ behaviours allow us to easily identify the subdomains of our applications.
Let’s assume we see a huge amount of traffic consulting the landing page, then 70% of those users are moving to the authentication journey (sign in, sign up, payment…), from here only 40% of the traffic subscribes to a service or use their credentials for accessing the service.
Users’ behaviours example in an application
Those are good indications about our users’ behaviours in our platform, DDD would suggest starting from the domain model of our application identifying the subdomains and their related bounded context and having behavioural data supports us on how to “slice” the frontend applications,
Users’ behaviours are invaluable for identifying our micro-frontends.
In the example discussed before, if we think about the technical implementation, allowing 100% of our users downloading only the code related to the landing page will allow them to have a faster experience because they won’t download the entire application immediately and the 30% of users who won’t move forward to the authentication area will have just enough code downloaded for understanding our service.
Obviously, mobile devices with slow connections can only benefit from this approach for multiple reasons: less KB to download, less memory used, less Javascript to parse and execute and a faster first interaction of the page.
Greenfield projects are a bit more complicated to manage, identifying micro-frontends upfront without knowing how our users interact with the platform could result in bad experiences but nevertheless, we have to find a way for structuring our micro-frontends architecture.
In this case, working closely with the product team or the subject experts could make a huge difference.
In my experience, any startup or medium-large organization have always a team or a person that has a clear idea of how the platform should behave, that knows inside out the core domain of an organization.
This person or team is key for understanding how the user should behave and therefore how to identify the domain model of our application as well as our micro-frontends.
It’s essential to understand that a subdomains evolves with the business, never assume that is immutable!
In DAZN we have decided to split our Single Page Application into multiple subdomains based on the data retrieved in the past years, ending up with 5 different micro-frontends with a few components developed by external teams and embedded as dependencies in one micro-frontend.
We identified the following micro-frontends:
. Landing page
. Authentication
. Catalogue
. Playback
. Sports data
. User account
. Help
. Chat
For instance, Playback and Sports Data are components living inside the catalogue micro-frontends, the complexity of those 2 subdomains lead us to assign a team dedicated to each of those subdomains.
Those components are published in an NPM private repository and are treated as an external dependency for the catalogue micro-frontend.
All the others are SPAs or single pages loaded by our client side orchestrator.
The power of local decisions
Working with subdomains allow us to assign a team to a specific area of our application, now stop for a moment and think how powerful could be this concept…
One of the key thing that I’ve always envy to startups is how fast they are capable to move and how quickly they take decisions on architecture, design or UX even.
When they need to take a decision, it’s a matter of minutes or hours but not weeks like in large organizations where we need to have a quorum of people agreeing on the solution.
If we think even further, a startup can react very quickly because they can take local decisions, in their case a local decision is a company decision, but if we extend this concept to medium-large organizations, dividing an application by subdomains allow us to have “multiple startups” inside an organization, therefore, empowering a team to take local decisions will allow to speed up the delivery, reduce the frustration and brings on the table interesting concepts like independent builds and deployments, less external dependencies, less frustration and more innovation.
The outcome of using DDD for identifying a ubiquitous language and subdomains would be creating a cross-functional team composed by frontend developers, backend developers, manual QAs and dev-in-test working closely to their product team/subject expert and being able to take a wide range of local decisions, from product decisions to infrastructure decisions, being responsible of the subdomain end to end.
Obviously, this team cannot (and shouldn’t!) be compared to a remote island where any decision is taken locally, these teams have to collaborate with the rest of the organization using services like architects, cloud experts and other functions inside the organization following the boundaries created by the heads of the technical department.
Organization example where each team represent a subdomain
In the past years, I read a lot about DDD and I found an interesting box inside Domain Driven Design Distilled book that caught my attention and I think is worth to share in this post to enforce the concepts explained in this paragraph:
Bounded Contexts, Teams, and Source Code Repositories
There should be one team assigned to work on one Bounded Context. There should also be a separate source code repository for each Bounded Context. It is possible that one team could work on multiple Bounded Contexts, but multiple teams should not work on a single Bounded Context. […]
It is especially important to be clear that one team works on a single Bounded Context. This completely eliminates the chances of any unwelcome surprises that arise when another team makes a change to your source code. Your team owns the source code and the database and defines the official interfaces through which your Bounded Context must be used. It’s a benefit of using DDD.
Last but not least, I think would be helpful having some takeaways of this post based on my experience and what I saw so far:
Gather data: if you have a legacy project you can use Google Analytics or similar services for understanding how your users are interacting with your application, you will find a clear idea how your user base is interacting with your application.
For greenfield projects, engage with your product team or customer, add GA or similar tools in your web application and via data validate the initial assumptions. Remember, bounded context and subdomains evolve with your business, are not defined once and set in stone!
Talk with the domain experts: invest time with your product team or the domain experts in your company, understand their point of view, their roadmap, how they think to evolve the project, those are vital information for identifying the micro-frontends
Review the teams organization: don’t fall in the trap of defining once the teams and don’t change them anymore, teams, like your business, should be fluid, if you see that following DDD there are some teams crossing multiple subdomains, make the bold decision reviewing the internal organization, the entire business will benefit from it!
A micro-frontend could be a single page or a SPA or SSR: as long you are following DDD for identifying your subdomains, a micro-frontend may end up to be represented by a single page like in the case of a landing page, or a more complex solution based on a Single Page Application architecture or a Server Side Rendering one.
Components risk being not representative of a subdomain because tightly linked to the container where they are nested, therefore the overlap of multiple contexts could cause more issues than benefits.
Invest the right amount of time at the beginning of your project: designing an architecture upfront is not the best way for starting a project, usually an architecture should work iteratively, therefore we should start designing “just enough” and slowly but steady we enhance the design based on additional information we found engaging with the product team, developers and users.
When you are identifying the different subdomains of your application invest enough time because this decision could impact how to structure the tech teams as well as how much communication overhead your company is going to spend due to dependencies between teams
How can we orchestrate our micro-frontends architecture?
Following the previous posts on micro-frontends (1 and 2), it’s time to talk about how to orchestrate micro-frontends.
First of all and foremost, there are 2 schools of thoughts about how a micro-frontend should look like, as explained in the previous article where I was explained different implementations of micro-frontends, there are implementations where a micro-frontend correspond to an area of the user interface, others where the micro-frontend is a SPA or a single page.
When we consider the micro-frontends implementation based on different logical areas of the application (like a header, a footer, a payment form and so on) we would face different challenges like:
Which team would assemble the aggregated view?
How can we avoid external dependencies in every team?
Which team is accountable for an issue in the aggregated view?
How do we ensure that a specific area of the application is not tightly coupled with the parent container?
How can we be sure there aren’t conflicts between dependencies?
Are we assembling at runtime or compile time?
If we decide to create the page at runtime time, is our application servers layer scalable?
Is the content cachable and for how long?
How do we ensure the development flow is not impacted by distributed teams?
And many other questions (technical and organisational) that could make our life way more complicated than how it could be.
Interestingly enough, this approach didn’t provide the expected benefits for Spotify working at scale and they reverted back to a more “classic” architecture based on SPA.
For the benefits of this post, let’s define our micro-frontends as SPA or single pages with a generation made at compile time in order to avoid any possible surprise happening at the composition layer.
Anyway, there are some challenges to face also with this approach, probably the main one is understanding how we want to orchestrate our micro-frontends and it is the focus of this post.
The orchestrator layer could be either on the client-side, server-side or edge-side; the solution depends on how “smart” the orchestrator layer should look like for our applications.
Server-side or edge-side orchestrator
A server-side or edge-side orchestrator would mean that for any deep-link or organic traffic hitting our domain has to be analysed by an application server or an edge solution (lambda@edge for instance), in both cases we need to maintain a map of URLs that correspond to static HTML files (aka micro-frontends).
For instance, if a user logs out from our application we should probably unload the authenticated micro-frontend and load the sign in/sign up micro-frontend, therefore the application server or the code running on the edge should know which HTML file to serve for every URL or group of URLs in the case we are going to work with SPAs.
This technique could work without any problem considering we can change quickly the micro-frontends map directly on the server without any impact on the client-side, but presents some potential challenges, like finding the best way to share data across micro-frontends considering there are some limits of storage inside the browser and doing too many roundtrips to the servers is not ideal in particular for slow connections.
Another challenge would be finding a solution for initialising the application, considering with micro-frontends we split the monolith into multiple subdomains, are we going to initialise the application every time a new micro-frontend is loaded? Are we going to use Server Side Rendering storing the configuration inside the HTML? How do we communicate between micro-frontends? How do we scale our application servers when there is bursty traffic?
Those are some of the challenges for implementing a server-side or edge-side orchestrator.
Client-side orchestrator
Another possible approach could be to create a client-side orchestrator responsible for:
— initialise the application
— sharing the application’s configurations to all the micro-frontends
— load/unload a micro-frontend based on the user’s state
— routing between micro-frontends
— exposing an API for interacting between a micro-frontend and the client-side orchestrator
One of the PROs of this solution is that you have more control over the application initialisation.
If well designed, the client-side orchestrator doesn’t need to change too often, therefore, will be fairly stable.
It provides additional functionality that could be used by various micro-frontends but it’s not domain specific, it’s also a great solution when our aim is to abstract our micro-frontends from the platform they are running on (browser instead of mobile devices or smart TVs).
The main CON is the initial investment in identifying which feature should be handled by this orchestrator because the risk of a big ball of mud is behind the corner, a bug on this layer could blow up the entire application and the implementation of new features, if not well co-ordinated, could slow down other teams creating a cross-team dependency.
In DAZN we opted for a client-side orchestrator that we called bootstrap.
Bootstrap has all the responsibilities listed above plus an additional one related to our use case, in fact, bootstrap is abstracting the I/O APIs of the platform where the application is running on, in this way each micro-frontend is completed unaware in which platform is loaded.
With this technique, we can re-use a micro-frontend across multiple smart TVs, consoles or set-top boxes without the need to rewrite specific device’s implementations, unless the implementation has memory leaks or performance issues.
Bootstrap is served every time a user types our domain in the browser or opens the application on a smart TV, it’s always present and never unloaded for the entire duration of the user session.
DAZN loading flow
Let’s try to expand further about the bootstrap in order to understand the main ideas behind it:
Initialise the application
Bootstrap should be responsible to set the application context, first of all understanding if the user is authenticated or not and based on the application initialisation we can load the correct micro-frontend.
Any other meaningful information your application needs for setting the context for the entire application should be managed at this stage.
It could be a static configuration (JSON) or dynamic one where an API needs to be consumed, either way, having an external configuration for our frontend allow us to change some behaviours of our system without the need of bootstrap releases.
For instance, a configuration could provide valuable information for the application lifecycle like features toggles, localised labels for the user interface and so on.
Micro-frontends routing
Bootstrap is definitely responsible for routing between micro-frontends, in our implementation, we have 2 routing spread between bootstrap and every micro-frontend.
Bootstrap doesn’t have the entire URLs map of our applications, instead, it loads in memory a map of which micro-frontend should be loaded based on the user status and the URL requested via user’s interactions or deep link.
Those two dimensions allow us to load the correct micro-frontend and leave to the micro-frontend code handling the URLs to manage inside different views that compose it.
A rule of thumb here is to assign a specific second level path for a micro-frontend so it would be easier to address the scope of a micro-frontend, for instance, the authentication micro-frontend should be loaded when the user types mydomain.com/account/*, instead, the micro-frontend for the help pages should be loaded when the user clicks on a link like mydomain.com/support/* and so on.
Inside every single micro-frontend, we can then decide to have additional paths like mydomain.com/support/help-page-A or mydomain.com/support/help-page-B, in this way the domain knowledge would be retained inside the micro-frontend without spreading it across multiple parts of the application.
The main takeaway here is that we have two types of routing in a micro-frontend application with a client-side orchestrator, a global one at bootstrap level and a local one inside the micro-frontend.
Micro-frontends lifecycle
As we mentioned before, each micro-frontends should be loaded via the boostrap, but how? Single-spa, for instance, uses a javascript file as an entry point for mounting a new micro-frontend.
In DAZN, we took a different approach because using just a javascript file for loading a micro-fronted would have precluded the possibility to use server-side rendering at compile time that was an interesting option for us to provide faster feedback to our user meanwhile they were transitioning from a micro-frontend to another one.
Micro-frontend anatomy: HTML, JavaScript and CSS files
Considering an HTML file is basically an XML file with a specific schema, bootstrap can load and parse the file appending inside itself all the relevant nodes for loading a micro-frontend using DOMParser, a standard interface for parsing XML or HTML strings.
Anything inside the body or head tags could be appended inside bootstrap’s DOM tree.
Potentially, we can also decide to define specific attributes for all the tags we need to append in order to have a quick way of selecting them.
Anyway, the overall idea is parsing an HTML file and appending inside bootstrap what is needed for loading the micro-frontend, therefore any external dependency (like a JavaScript or CSS file) present in the micro-frontend HTML file will be appended and therefore loaded by the browser.
A huge benefit of this neat approach is that it’s not opinionated, anyone can start working on a new micro-frontend without learning the way we decided to deal with micro-frontends because at the end, as long the micro-frontend output results in the Frontend holy trinity: an HTML, a JavaScript and a CSS files.
I captured a video throttling the connection in order to show how the bootstrap appends the DOM elements inside itself, as you will see there are 4 phases:
— identifying the micro-frontend to load,
— load the HTML of the micro-frontend,
— parse it,
—append the relevant tags for displaying the micro-frontend in the page.
It’s a very simple but effective mechanism!
An additional feature added to each micro-frontend is the possibility to perform some actions after and before are mounted or unmounted, in this way the micro-frontend can do any logic for cleaning up any object appended to the window object or any other logic to run in one of the 4 lifecycle’s methods mentioned before.
Bootstrap is responsible to trigger the micro-frontend lifecycle methods and clean the memory before loading the next micro-frontend, this action ensures no conflicts are happening in different or the same versions of a library used by different micro-frontends.
Bootstrap memory and dependencies management
It’s time to deep dive into the micro-frontends memory management, considering bootstrap is loading one micro-frontend per time, as explained in the previous post, and each micro-frontend is not sharing any library or dependency with another micro-frontend, we could end up in a situation where a micro-frontend is loading React v.15 and the next one React v.16.
At the same time, we want to have the freedom to pick any technology and library version inside every micro-frontend because the development team that retain the business and technical knowledge should make the best implementation choice available instead of having constant trade-offs across the entire application as usually happens when we work with a Single Page Application.
At this stage, I believe is very easy to guess the challenge we are facing because any library or framework used by a micro-frontend will append objects on the global window one and in Javascript we cannot directly control the garbage collector but we can facilitate the disposal of an element removing all the references and instances of a given object.
For achieving this goal, an additional bootstrap responsibility is keeping track of any object that is appended to the window object by any micro-frontend and cleaning the window object after unloading the micro-frontend but before a new one is loaded (the joy of metaprogramming in JavaScript 🎉). Bootstrap takes a snapshot of all the keys appended to the window object and removes them before loading a new micro-frontend, in this way we keep track of what should be removed without duplicating any objects in memory and with a simple iteration of this array we delete any objects used by the unloaded micro-frontends inside the window object.
APIs layer for communicating between bootstrap and a micro-frontend
The last bit worth mentioning is the APIs layer exposed by the bootstrap via the window object.
If you asked yourself how we share data and communicate between micro-frontends, bootstrap is the answer!
Remember that our implementation is based on the assumption we always load one micro-frontend per time and we slice a micro-frontend based on a subdomain of our application, you will soon realise that the data shared across micro-frontends are not happening too often if you work well in the initial session where you define all your subdomains.
Sharing data between micro-frontends is pretty easy, bootstrap shares some APIs for storing and retrieving information accessible by any micro-frontends, it’s up to you deciding which storage is more convenient for your implementation and what kind of limits you wanna add to the objects to store locally.
Considering the bootstrap is a tiny layer written in vanilla JavaScript in between a platform and a micro-frontends and it’s initialising the application, we need also to expose an API layer for abstracting the I/O layer for storing or retrieving information from and to a micro-frontend.
Working with multiple devices require to have different APIs for storing and retrieving files because web storage APIs are not always consistent across all those platforms.
Another important part to highlight is the configuration retrieved from a static JSON file or an API that usually is shared with all the micro-frontends to understand the context where they are running (for instance sharing particular configuration based on the country or languages).
The most important thing when we design the APIs exposed by the bootstrap is trying to be forward-thinking because the bootstrap should be a layer that doesn’t change at every release otherwise you could break some contracts with micro-frontends and coupling the micro-frontends to bootstrap functionalities could jeopardise all the great work done splitting up your business domain in multiple subdomains.
Summary
During this post, we have explored the possibilities for orchestrating micro-frontends, we deep dive into the client-side orchestrator that in DAZN is called bootstrap, in particular, we have seen the benefits and the challenges of this approach and how we have managed to solve them. In particular, we saw the bootstrap has 3 main responsibilities:
— routing between micro-frontends (load, unload and lifecycle methods)
— initialise the application
— exposing an APIs layer for micro-frontends communication and web storage
One of the questions I received very often after sharing those posts is if and when the bootstrap will be open-sourced, the answer is that we are thinking about that but we cannot commit to a timeline at the moment (that’s also the reason why I didn’t share code in this post, sorry again 🙏).
I really hope you are getting a clearer idea of how to structure your next micro-frontends project if not feel free to reach out, so I can have food for thoughts for the next post! ✌️
Considering the great feedback of the first post on micro-frontends and the questions received about the approach we are taking in DAZN, I decided to share a bit more about this topic.
In this post, I am covering one of the many possible implementations of a micro-frontends architecture.
Despite micro-frontends are a new model for our frontend applications, many companies tried to embrace the principles behind them and they have created multiple implementations for solving their frontend and organisation challenges.
I think is worth mentioning some of them before jumping in how we have designed our implementation, this is not an exhaustive list but it’s interesting being aware of the different possibilities available:
— Spotify uses micro-frontends in their desktop application leveraging iframes for stitching together different part of the same view.
The communication between iframes is made via an event bus that decouples nicely the different part of the application allowing them to communicate without knowing who is going to listen for a message or event.
Also, this approach saves a lot of time on managing the application memory because every time we change the iframe location, automatically all the objects are ready to be garbage collected.
Spotify’s micro-frontends approach
— IKEA decided to implement micro-frontends with a different approach, they are using Edge Side Includes (ESI) mixed with Client Side Includes (CSI), I don’t wanna spend too many words on this technique because it’s extensively covered in Gustaf’s post but it’s definitely another opportunity for generating dynamically the content of our pages and cache the result on the CDN level or client side, depends the approach we wanna take.
— OpenComponents is an interesting framework used by several companies like Skyscanner or OpenTable. OpenComponents is an opinionated framework that is levering the concepts of an end to end components (frontend + backend together) submitted to a register and used for composing an application.
Also, in this case, we can find a lot of information on OpenComponents project website
In between those 3 implementations, we can find similar flavours with some differences used by medium-large size organisations for creating independent and technology agnostic micro-frontends. It’s worth mentioning Zalando or BuzzFeed for instance as other contributors in this school of thoughts.
If we wanna summarise the implementations we discussed till now we can list the 3 different approaches:
. using iframes + event bus
. using ESI in conjunction (or not) of CSI
. using OpenComponents or similar runtime/compile time template systems
The “DAZN way”
As I mentioned at the beginning of this post, there is another implementation to discuss: the approach taken in DAZN.
DAZN is an OTT service available in several countries that streams live and on-demand contents. Our application is available not only on web and mobile but also on smart TVs, set-top boxes and console, and that’s important to highlight because we often face unique challenges and we need to think out-of-the-box for solving them.
Usually, when we start a micro-frontends project, we should ask ourselves several questions and based on the answers facing the challenges related to our decisions, for example:
· do we want multiple micro-frontends in the same view?
· how do we route between pages?
· how do we share data between micro-frontends?
· how do we generate our micro-frontends? Runtime or Compile time?
Let’s try to answer all those questions for understanding the approach we embraced…
Do we want multiple micro-frontends in the same view? No, we want to have 1 micro-frontend loaded per time in this way we don’t have share dependencies between micro-frontends, every micro-frontend is small enough but not too small, we have full control on the final outcome, it’s technology independent and well encapsulated.
We can potentially work with different versions of the same framework without impacting other micro-frontends or even with different technologies without any impact on the overall application.
We follow Domain Driven Design (DDD) practices for slicing our subdomains and make them really independent mapping the product teams structure and creating a vertical inside a large organisation composed by product people + frontend developers + backend developers + manual QAs + devs in test, and this is very powerful for moving fast, with different speed between teams when is needed in large companies.
Bear in mind that more often than you think, our applications are not entirely consumed by users, for instance, when the user is authenticated, all the code and the dependencies of the sign in/sign up micro-frontend won’t be loaded because we load only the micro-frontends of the authenticated area.
At the same time, when a user is not authenticated, it’s not 100% sure that she is going to finish the on-boarding journey and successfully access the authenticated area of your application, check your stats on how your users are interacting with your application and if you don’t have them invest the right amount of time on creating the right observability with tools like Google Analytics, Sentry, LogRocket and so on.
Remember, micro-frontends are helping a lot achieving the goal of loading only what the user needsand not more than that.
How do we route between pages and how do we share data between micro-frontends? There are several ways we could achieve that, on the backend, on the edge or on the client side. We choose the client side creating an orchestrator called Bootstrap that has 4 main goals:
· route between micro-frontends
· load and unload a micro-frontend (1 per time, never multiple)
· initialize the application retrieving the configuration
· expose an APIs layer for sharing data between micro-frontends
How do we generate our micro-frontends? Runtime or Compile time?
We prefer to be very predictable with the outcome of our artefacts and we want them highly cachable like a SPA would be, therefore we didn’t take the path of creating anything at runtime, but we prefer generating micro-frontends at compile time, store them on AWS S3 and serve via Cloudfront CDN.
In this way, we don’t have to worry about scaling our infrastructure or unpredictable edge cases happening when we serve our application, we can run end to end tests and performance test before deploying in production having more confidence of what we deploy before being live.
The architecture
In our case, we decided to split the application into multiple subdomains studying upfront how our users were interacting with our web application. For green-field projects, I recommend to deeply understand how your users are going to interact with the application in conjunction with your UX and Product team and follow Domain Driven Design for defining the subdomains and their associated bounded-context.
For the DAZN application, almost every subdomain technically translates into a Single Page Application, but there are some exceptions, for instance, the video player is a component due to the broad scope of that subdomain, then those components are imported inside a micro-frontend as any other library.
Micro-frontends are loaded and orchestrated by the bootstrap, a simple vanilla javascript application embedded in the main HTML page that loads different micro-frontends based on deep-link requests, user status or any request coming from the loaded micro-frontend.
This is how our architecture looks like:
Bootstrap is always available during the application lifecycle
Bootstrap is always available during the lifecycle of our application, it’s responsible for loading our micro-frontends and exposing a tiny layer of abstraction between the device and the micro-frontend.
This detail becomes even more relevant when you target multiple devices and not only web browsers, we have our applications available on many smart TVs, set-top boxes and consoles, all of them have often different requirements and I/O APIs that defers and can be encapsulated at the boostrap level.
In this way, we can run a micro-frontend in multiple devices without the need to change a line of code because the bootstrap is abstracting the platform where the micro-frontend is running on.
If we wanna summarise how the application loads inside a browser we could say:
users request our web application typing our domain in the browser
bootstrap is served
bootstrap initialize the application retrieving some configuration from the APIs layer
based on the initial state and the user request (deep-link or default URL) load the correct micro-frontend
the user enjoys our web application based on micro-frontends 🥳!
Bear in mind that every micro-frontend is independent, therefore we are not sharing components or logic across micro-frontends.
If you think it is a waste of time and effort you won’t believe how much independence every team has got thanks to this decision.
Code duplication is not always a bad practice as we have learnt in the past, often cross-team dependencies and code abstractions risk to be way more dangerous and tedious than creating 3 or 4 times the same component.
We have noticed that spending the right amount of time analysing the user flows and identifying the subdomains lead to way less duplication than expected.
Also, we noticed using micro-frontends, the dependencies across teams didn’t happen too often like in other projects thanks to the initial effort on analysing the project and create meaningful subdomains.
If in your case it’s an absolute must re-using components, there is a way to mitigate the duplication using web components for standardising the component code, with this technique, it could be reusable in combination with any framework, but this is a discussion for another post 😉.
When we started this journey into micro-frontends, for me was very clear that I had to think for the future of the development teams and not only solving the technical aspects.
With micro-frontends, we were able to provide the independence I was looking for without impacting the speed of delivery, each team is owning end to end a specific domain guaranteeing an easy way to add new functionality, fixing a bug or add an improvement without risking to have a knock out effect on the rest of the application or dependencies spread across our multiple dev centres.
Having shared those information several times with new developers joining the company as well as during my talks or online workshops I know you could have millions of questions around the bootstrap, how it loads a micro-frontends, how it shares data and so on.
I will answer all those questions in the next post that will be focused on bootstrap only so follow me for not missing this deep dive inside the micro-frontends world.
If you have any curiosity or question about micro-frontends feel free to get in touch, I’m always keen to help the community as much as I can 😁!
In the past 30 months, I had the opportunity to work on one of the most challenging architectures I’ve ever designed in my career.
The main requirements were based on the speed of delivery, scalability and code quality.
Frontend applications are becoming more challenging daily and achieving those requirements in a company with a massive growth like DAZN was far to be an easy task.
The first step for me was identifying how to achieve those requirements in a meaningful manner, therefore, I started thinking how I can reach those goals in an ideal world and then work retrospectively through the constraints we had inside our company.
The speed of deliverycould have been achieved parallelising tasks in multiple teams the real challenge although is having teams independent enough to not be stopped by external dependencies in particular when the teams are distributed and not co-located.
Scalability on the Frontend ecosystem is not only represented by technical challenges but mainly by autonomous teams, too often I experienced the frustration of frontend developers from external dependencies and because they have to maintain and improve a codebase started for one purpose and evolved in a monster becoming unmanageable after some months or a few years of work, ideally we should be able to scale our teams organically and adapting them to the business needs without too much friction, more than being trapped inside codebases that do not really follow the “business rhythm”.
Code Quality is a non-functional requirement that is always aimed by any team and company out there but often, despite the goodwill of each team members, due to pressure from the business, we had to make some hard decisions cutting some corners so the tech debt increases and, without being addressed properly, having a knock-out effect on the entire organization and the teams morale.
On top of those key goals, a personal one I thought was key for the project I was about to redesign was innovation, in the JavaScript community there are plenty of talented teams and individuals that are contributing to open source projects with great libraries, frameworks but more in general solutions, that could make our life easier or even accelerate the time to market of specific feature, ignoring this fantastic ecosystem would have been a technical suicide considering I was working on an architecture for the future that should have remained in the company for the foreseeable future.
For achieving all of these goals I had to think outside the box, leveraging the past experiences and the learnings from successes as well as failures happened in my career.
It’s then that I thought about micro-frontends, following the microservices principles, I was able to extract a manifesto based on what I need to achieve:
DAZN micro-frontends manifesto
Usually, when we design new architecture we need to bear in mind that architecture and technical decisions are not affecting merely the code and our technical teams but also the entire organization we work for, therefore is essential understanding the impact of those choices across our company.
If you wanna learn more, I summarise this incredible journey in this talk with my colleague Max Gallo during the last edition of Frontend Developer Love Conference, the feedback at the conference was really positive, but I decided to use this platform for understanding what other people think and create a genuine discussion around a topic that is going to change the future of our Frontend applications: micro-frontends.
Enjoy the talk and feel free to comment or ask any questions, I’d really like to gather the experience and common questions/doubts of the community around micro-frontends doing my best to answer them all.
This morning during my commuting time I read a post on Lit-HTML and this templating library intrigued me at the level that I needed to experiment as soon as possible, so I took a night off because I was curious to see this new approach in action.
DISCLAIMER: If you are an expert on Lit-HTML I beg you pardon if I didn’t report all the latest on lit or some information in this post are not up to date 😅 but if you are a curious like me 🤠, you may have found the right place understand what Lit-HTML is and why I was excited to try it 😇.
What is Lit-HTML?
Lit-HTML is a blazing fast template library that will be used for the new version of Polymer (v 3.0), it was presented during last Chrome Dev Summitin San Francisco and I warmly suggest to invest ~30 mins of your time watching the following talk for getting an idea of the library:
If you don’t have 30 mins right now here a summary of what lit-HTML is doing.
Lit-HTML doesn’t use Virtual DOM like the latest trends in many UI libraries like React or Preact for instance, but instead is using web standards to generate and update a UI component.
In fact, this library uses the <template>tag and ES2015 tagged template literals for generating a DOM node.
With this approach, lit-HTML is capable to analyse the template literals and update only the mutable part maintaining the static bit unchanged increasing the render performance compared to the virtual DOM approach.
To provide an idea of how lit-HTML differs from a VDOM library I created these animations so you can immediately see the work done by one and the other library for updating a DOM node value and an attribute:
with Preact (or React, both behave in the same way):
with lit-HTML:
As you can see, lit-HTML heavily optimise the updates just recalculate what effectively should be re-rendered instead of re-rendering the entire node, this behaviour is highlighted in the first h1 tag of our example: Preact is re-rendering the entire node including the text that is static by design (“Preact” word was static, the number instead is a random one I used for causing a DOM update), instead lit-HTML splits the string in what is static and what is not so it can update ONLY what potentially could change without the need of re-rendering anything else.
If you are wondering what is the black magic behind lit-HTML, I can summarise it in this way: JUST WEB STANDARDS!
Surprisingly enough, lit is not using anything too complicated but just web standards, when we define a template to render with lit-HTML we write a component like that:
As you can see it’s just a function returning a tagged template literal, the tag correspond to the word html provided by lit-html library. Tags in templates literals have the characteristic to manipulate the template before being returned, in fact the tag is usually a function that is intercepting the output of a template literal before being returned.
The html tag, provided by lit library, is analysing the template before returning it to the render function used for updating the DOM, if we output on console how our template becomes before being rendered, we can see that the html tag is performing an analysis for dividing what is static, what is dynamic and creates an array of raw data:
For benchmarking lit-HTML, I created a simple test with some random HTML elements updated every 500ms.
Looking at the performances, the node values or attributes update or the subtree update inside a template is incredibly fast compare to the VDOM approach.
This is noticeable also with not nested components like the ones above, I run several tests on them and this is the outcome:
These data are reporting how long did take on the average of several DOM updates.
We can see in the image below that sometimes Lit-HTML was even faster than the values inside the table and sometimes a bit slower, but comparing with Preact (and also React because I tried both), Lit-HTML is really consistent time wise, the discrepancy between an update and the other is really small.
Lit-HTML is definitely loosing against Preact or React on the first time render, in fact I noticed that Lit-HTML is on the average 60–70% slower just for the first few renders, after that is blazing fast compared to the VDOM one.
Also, after 10-15 mins of keeping the test up and running, I noticed the 2 components weren’t on sync anymore and apparently the Preact one was a tick behind the lit-HTML one.
It’s worth mentioning how I was able to retrieve these values so you can try your own tests as well if you like.
After creating a Preact and a Lit-HTML component, I used the performance APIs in the following way:
Before returning the html to render I added the starting mark with the following code: performance.mark('litStarts’)or performance.mark('reactStarts’)
Then, using the MutationObserver object I observed every change to characterData, childList or subtree calculating the time it took to update the DOM with the final mark andmeasure method from performance APIs:
Let’s observe now how a lit-HTML component is created, the 2 essential parts are the html tag used or analysing the template literal and the render method used for updating the DOM, this is a simple lit component:
The render method has to be called every time there is a template update, in order to do that we can create our own logic via setInterval or requestAnimationFrame or any other way will trigger the render method after changing a value inside the template (proxy or reactive programming could be other 2 interesting methods to try).
A more in depth explanation could be find reading this article: A bit about Lit-html rendering.
Luckily, lit-html is integrated in the next version of Polymer (v3.0) therefore we won’t need to spend much time wrapping this template engine inside custom code for creating our components library.
Bear in mind, as highlighted in the Polymer repo, LitElement is not ready yet for production but we can start experimenting with it.
LitElement is currently in development
Considering Lit-HTML is a standalone template library, if you are not comfortable on using polymer you can always create your own components library 🤩🤟 and integrate it with your favourite state management!
Other online resources
Before finishing this quick article, I thought would be useful sharing additional resources for understanding a bit better lit-HTML, hopefully you will find them useful
When I tried for the first time Visual Studio Code on my Mac I remained quite impressed about its performances.
The investment Microsoft did during the last few years on this editor is really remarkable, considering also that it’s an open source software and not a commercial one.
As you know with Visual Studio Code you can create your own extensions and then share with the community inside the marketplace.
This for me was just an interesting and quick pet project before going back the my reactive studies, but it is worth to share it
I created a simple extensions for retrieving all the annotations in my Javascript projects grouping per categories inside the output panel or in a markdown file.
You can download the extension called vscode-annotations directly from the marketplace or inside the extensions panel in Visual Studio Code editor.
If you want instead take a look to the source, feel free to clone the project from Github.
First steps
If you wanna quickly start working on an extension, there is a Yeoman generator provided by the Visual Studio Code team that will create the folder structure and the necessary files for publishing your extension later on.
In order to use it just run these commands in your terminal window:
npm install -g yo generator-code
yo code
During the generation, the interactive generator will ask if you prefer working with Typescript or pure Javascript, in my case I picked the latter one.
After that you will have your project ready and you can start to have fun with Visual Studio Code!
if you prefer start with the classic Hello World project feel free to check Microsoft tutorial.
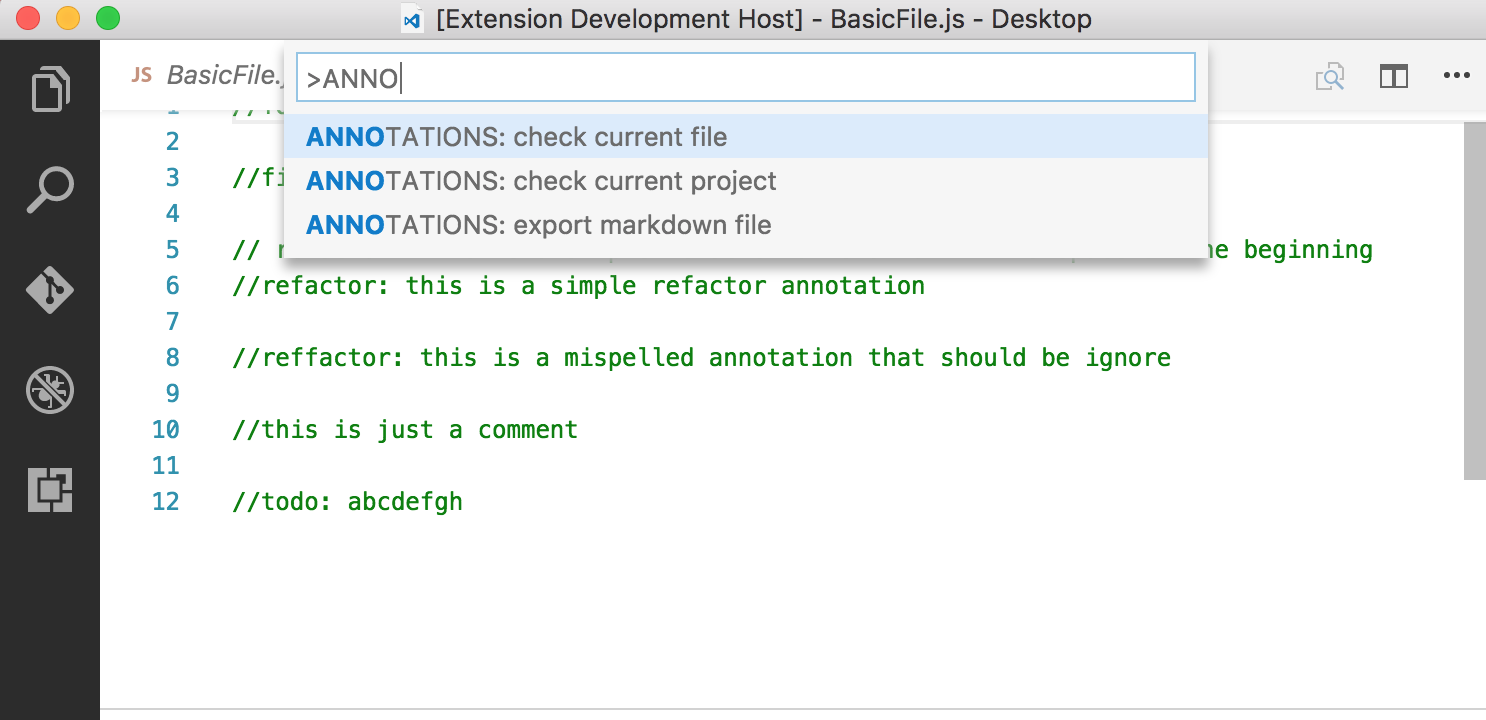
In my annotations extension what I’ve done is just providing 3 commands available in the command palette (CMD+SHIFT+P or View > Command Palette) :
. output all the annotations in the file opened inside the editor
. output all the annotations in a specific project
. export all the annotations in a specific project to a Markdown file
The first two will create an output panel inside the editor showing the annotations present inside a specific file or an entire workspace, the third one will create a markdown file with all the annotations for a specific project.
When you want to create a command inside the command palette, you need to set it up in few files, the first one is the package.json:
so in the commands array we are just defining the label that will be inside the command palette and the action that should be triggered when the user selects a specific command.
Then we will need to add each of them in the extension.js file (created by the scaffolder) inside the activate method that will be triggered once the editor will have loaded your extension:
vscode.commands.registerCommand('extension.getAnnotations', function () {
// extension code here
});
Just with these few lines of code you can see the expected results of having your commands present in the palette
Microsoft is providing a well documented APIs for interacting with the editor, obviously, because it’s based on Electron bear in mind that you can also use Node.js APIs for extending the functionalities of your extension, for instance to create a file or interacting with the operating system.
Working with the workspace
When you want to interact with the editor manipulating files or printing inside the embedded console you need to deal with the workspace APIs.
In order to do that you need to become confident with a couple of objects of the vscode library:
window
workspace
With window and workspace you can handle end to end the editor UI and the project selected.
Window object is mainly use to understand what’s happening inside a file meanwhile an user is editing it.
You can also use the window object for showing notification or error messages or change the status bar
With the workspace object instead, you will be able to manage all the interactions that are happening inside the menu or editor interface.
Workspace object is useful when you want to iterate trough the project files or if you need to understand which files are currently open in the editor and when they will be closed for instance.
In my extension I used these 2 objects for showing a notification to the user:
vscode.window.showErrorMessage('There aren\'t javascript files in the open project!');
Considering you are developing an extension for an editor you can easily debug what you are doing simply running the extension debug mode (F5 or fn+F5 from your macbook).
Few suggestions regarding the debug mode:
console.dir doesn’t work, console.log will substitute what console.dir does if you are inspecting an object but not an array!
when an error occurs it’s not very self-explained (kudos to Facebook for the react native errors handling, best implementation ever!) so you will need to follow the stack trace as usual
Publishing an extension
Last part of this brief post will be related to the submission of your extension to the Visual Studio Code marketplace.
Also in this case Microsoft did a good job creating an extensive guide on how to do that, few suggestions also in this case:
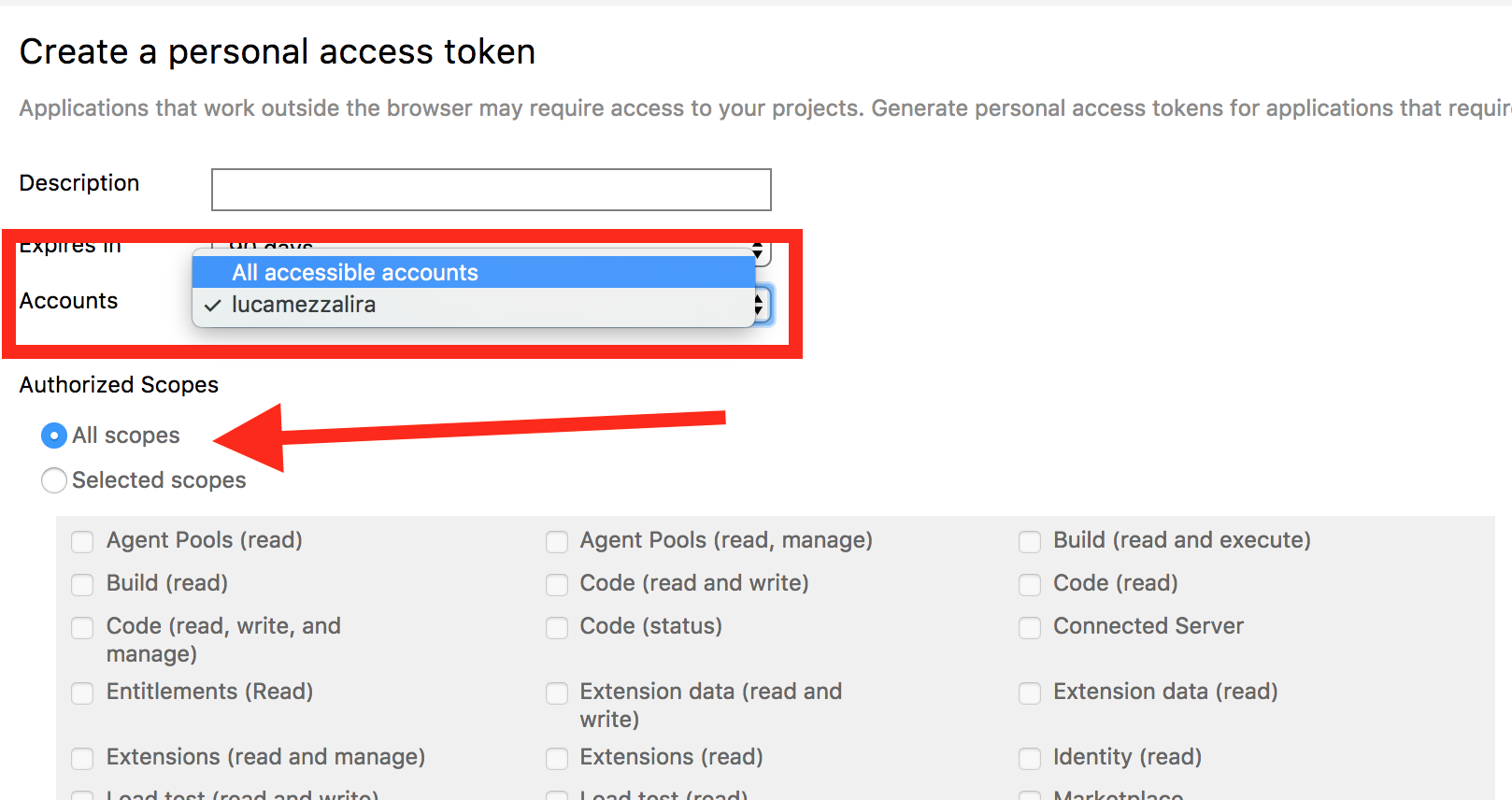
in order to submit an extension in the marketplace you will need to create a Microsoft and a Visual Studio Team Service accounts
when you create the Personal Access Token for publishing your extension, bear in mind to set access to all accounts and all scope otherwise you could end up with a 401 or 404 error when you try to publish the extension
vsce command line tool is pretty good in order to create a publisher identity and super fast to publish an application on the marketplace.
Considering that is a CLI tool you can also automate few part of the publishing process (increasing release number for instance) adding a scripts in your package.json
to make your extension more accessible in the marketplace, remember to add the keywords array inside the package.json with meaningful words and the appropriate category, at the moment there are the following categories available:
Debuggers
Extension Packs
Formatters
Keymaps
Languages
Linters
Snippets
Themes
Other
Wrap up
There could be tons of other things to do and to discover for developing a Visual Studio Code extension but I think that could be a good recap of the lessons learnt for creating one that you could use along with the Microsoft guide.
I spent last few weeks investigating on HTTP2, the successor of HTTP1.1 and I’d like to share my findings and thoughts in this post.
Let’s start saying that if the question you have in mind at this point is: “Can I really use it today, not only for experiments but also in production?”
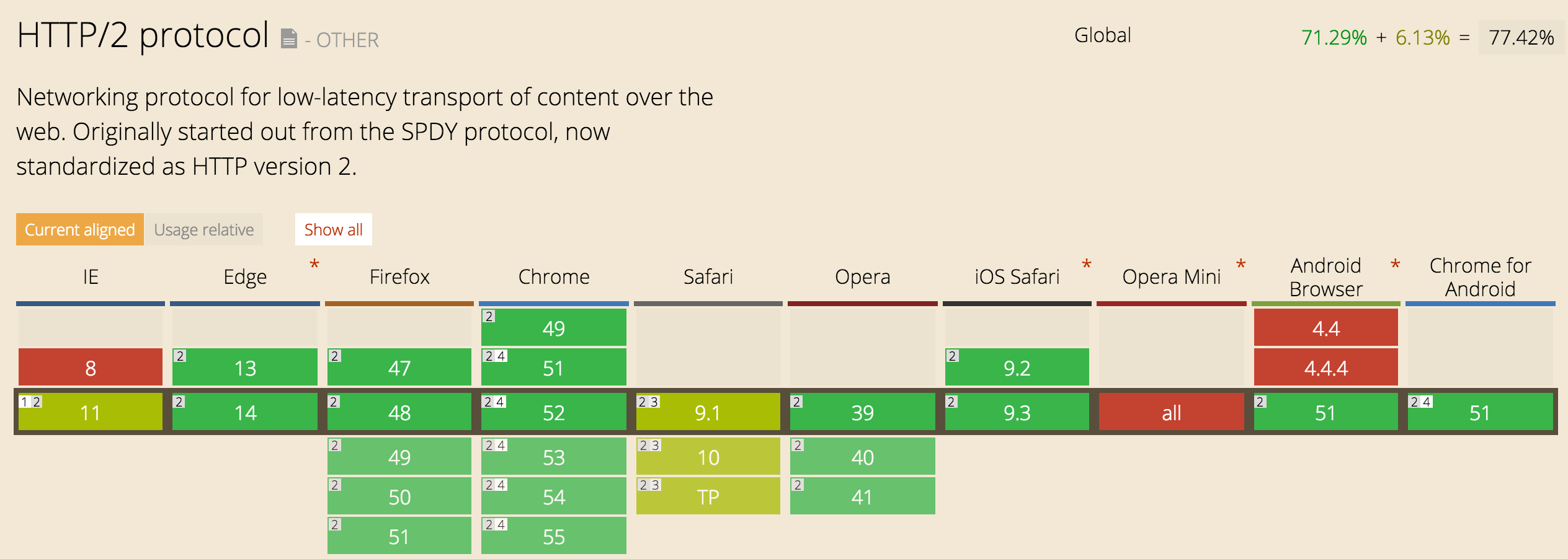
My answer would be: “YES, you can!”
As you can see from the screenshot taken from caniuse.com it’s definitely well supported on the latest version of the major browsers with some caveats obviously.
If you are not convinced yet, please check this website with one of the browsers that currently supports HTTP2 and look how fast to load is!
I’d suggest to install the HTTP2 indicator Chrome extension to discover how many web apps or online services are using this protocol:
Not yet convince?! OK let’s move to a deeper analysis then!
HTTP2 is a binary protocol with a multiplexing requests method implemented, that means all the browser requests will be handled asynchronously.
This massive change will increase drastically the performance of your application.
Considering at the moment a browser can download simultaneously a maximum of 5 resources per domain (let’s avoid talking about “resource sharding” for now), with HTTP2 we will be able to request all the resources and render them when the browser will accomplish their download, check this demo made with Go Lang for a proper comparison between the 2 protocols and check also the Network panel in the Chrome Dev Tools or Firefox dev tools in order to understand how the 2 protocols differ.
The Good
HTTP2 has really few rules in order to be implemented:
it’s backward compatible, so if a browser or a device where your application is running, don’t support HTTP2 it will fall back to HTTP1.1
it comes with great performance improvements out-of-the-box
it doesn’t require to do anything on the client side but on the server side for a basic implementation
few new interesting features will allow to speed up the load of your web project in a way that is not even imaginable with HTTP1.1 implementation
Despite the short list, HTTP2 is bringing a substantial change to the internet ecosystem.
One of my favourite feature is the server PUSH where a server can pass a link header specifying what the browser should download in advance before starting to parse entirely the HTML document.
In this case, we can educate the browser to download several resources like images, css or even javascript files before the engine recognise them inside the DOM, providing a better user experience to our web apps and/or games.
The Bad
There is still plenty of works to do in order to have a great penetration of this protocol, few specs are still on going (read the next paragraph: the ugly) and probably it will take quite few months before we will see a lot of services moving to this new protocol.
A part from the high level overview of the downsides, let’s look what will change on the technical side.
Considering that HTTP2 is not restrict on the amount of requests a browser is doing in order to download resources few techniques for optimising our websites will need to be reviewed or even removed from our pipeline.
Delivering all the application inside a unique javascript file won’t have any benefit with HTTP2, so we need to move our logic downloading only what we need when we need it.
Knowing that downloading large files won’t be a problem we could use sprites instead of several small images to handle the icons of our website.
Probably the different tools like Grunt, Gulp or Webpack will need to review their strategies or update their plugin in order to provide real value to this new project pipeline.
The Ugly
Google Chrome protocol implementation!
Chrome is my favorite browser and I use it extensively, in particular, when I need to debug a specific script or I need to gather metrics from a specific behavior of a web app.
At the moment it’s the only browser that requires HTTP2 server negotiation via ALPN (Application-Layer Protocol Negotiation) that basically is an extension allowing the application layer to negotiate which protocol will be used within the TLS connection.
Considering that OpenSSL integrates ALPN only from version 1.0.2, we won’t be able to enable HTTP2 protocol support for Chrome (from build 51 and above) if we don’t configure our server correctly.
For instance, on Linux OS, only Ubuntu from version 16.04 has that OpenSSL version installed by default, for all the other major Linux version you will either install the newer version manually or you’ll need to wait for the next major OS release.
I’d suggest reading carefully the article that describes this “issue” on ngnix blog before you start to configure your server for Chrome.
Wrap up
HTTP2 is not perfect and probably is not supported as it should be but, definitely, could improve (drastically in certain cases) your web project performance.
A lot of “big players” are already using HTTP2 protocols in production (Instagram, Twitter or Facebook for instance) and the results are remarkable.
Why not starting catching up with the future today?
In the past few weeks I was figuring out how to solve a problem of a chatty communication between client and server considering that we are close to the release and I have already got few ideas in mind to improve the product I’m working on right now.
Thinking to possible solutions I thought to search online few different approaches that could help me out to solve the problem, at the beginning I was thinking to refactor the REST APIs in order to create them closer to what the UI needs (backend for frontend pattern) but then I remembered that I had bookmarked few projects that could help me out to implement this pattern without reinventing the wheel.
So on friday night I started to investigate Falcor.js, a library made by Netflix that was trying to solve exactly my same problem and they honestly solve the issue in a really smart way.
Let’s imagine you have a client that needs to call several REST end points in order to aggregate the data for a specific view, independently from how large is the amount of data to retrieve you have to bear in mind few other drawbacks like:
latency
no caching on specific data because they are real time data or tight to a specific user
amount of data to display in a view (maybe without a paging API available to split them in several views)
pre-flight calls for CORS end points
internet connection speed (mobility vs home vs office)
content negotiation
All of these, and probably many others, could be causes of a bad user experience and quite often we postpone to address these problems after the release of our online products.
So if we can minimise the impact in somehow we could provide a better user experience and therefore our products could be faster, more interesting and raise a good success with our users also when they have poor connection signal on their favourite device.
Here is where Falcor.js comes in support, in fact with Falcor we can minimise the amount of calls to specific end points because this library is leveraging the idea of a unique data model that could be interrogate by our clients asynchronously via Falcor APIs optimising the amount of queries to it under the hood.
The query system allows not only to fetch data from Falcor model but also to get only the data you need to use in a specific view.
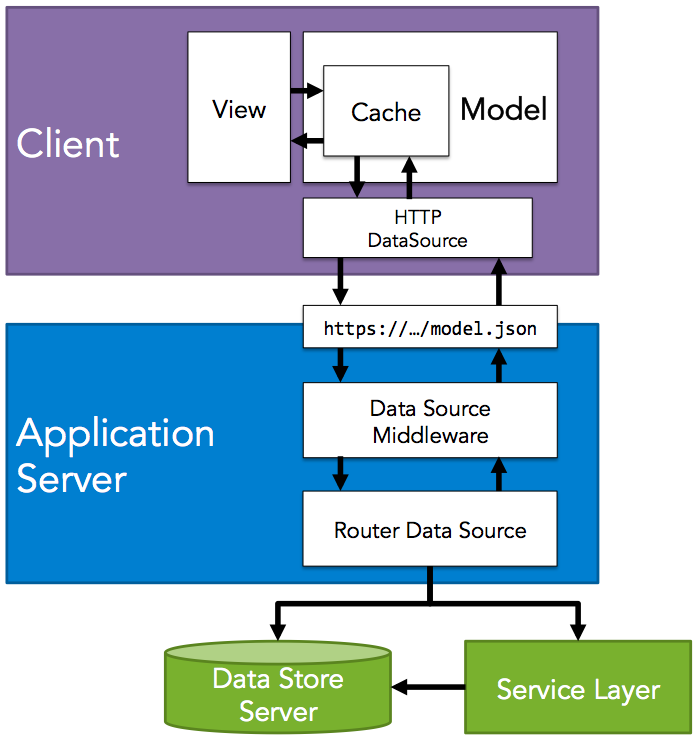
Looking at the image above you can spotted immediately the possible problem that Falcor solves brilliantly with a unique model.
In fact the Router is aggregating data from different end points and therefore the client can request exactly what needs in a nice and simple way.
The client will create a connection to a JSON model using the HTTPDataSource provided by Falcor.js client library that will allow to start the connection between the client and the backend data model.
On the backend a Falcor router is created and inside this instance there will be the description of the different queries available and what are the data to return as router system.
Doing this each client will download only the data that effectively needs to render the page and not an element more (sometimes reducing drastically the amount of data to load).
Also each client won’t need to interrogate ad hoc services for retrieving ad hoc data created for it but will just query the same data model created for the entire application only querying different end points.
As you can see from the diagram above this part sits between the client and your backend system creating a middleware that could be use only for specific end points or for the entire application.
Another interesting characteristic of Falcor is how it can optimise the query to the data model, in fact activating the batch mode, Falcor will gather all the queries to a specific route in a tick of your application performing all of them and possibly optimising to a unique roundtrip the requests instead of multiple roundtrips!
Last but not least Falcor allows you to query the APIs implementing a paging mechanism when you are iterating elements inside lists. For instance if you have an array of elements to display in your view but the APIs provided by the backend team don’t include any paging parameter, Falcor helps you via the query system, retrieving only a certain amount of elements via the paging mechanism.
So after watching the few videos available on Falcor and reading all the documentation in the website I started to experiment directly on the chatty issue I’ve got in my project.
I can’t really share the code I’ve used for my spike mainly because I’m using the product end points but I can share with you some benchmarks and thoughts on that for now.
Currently the catalogue I’m working with is composed by 5 calls to 5 different end points in order to display THE catalogue inside the view.
There is also a timer where every few minutes these 5 calls are performed again in order to retrieve new data that possibly could refresh the products available for the user inside the page.
Obviously behind the scene the application is doing several other calls in order to synchronise its status and performing some checks, but for now let’s focus only on the catalogue part.
I extracted the 5 calls in a simple HTML page replicating the current situation in the product and gathering some metrics to understand which was the starting point and how much Falcor would be able to improve the situation.
These are the benchmark I’ve retrieved for 5 XHR calls to different end points when the data are cached and when they aren’t:
NO CACHED XHR (after 5 calls):
average time on 10 tests ~678ms
average kb on 10 tests ~111kb
CACHED XHR (after 5 calls):
average time on 10 tests ~126ms
average kb on 10 tests ~3.1 kb
Then what I did was implementing a Node.js gateway where using the Falcor Router and the Falcor model I was able to query only the data I needed (and not downloading the entire JSON with information not needed for that specific view), I’ve optimised the query to the Falcor model via batching requests and these are the results with Falcor in place in front of the product APIs:
NO CACHED WITH FALCOR (Falcor optimise the 5 calls to only 2 calls):
average time on 10 tests ~32ms
average kb on 10 tests ~5 kb
CACHED WITH FALCOR (Falcor optimise the 5 calls to only 2 calls):
average time on 10 tests ~10ms
average kb on 10 tests ~406 bytes
This is really a good performance boost considering the amount of data we downloaded by default that are now optimised via Falcor queries; several roundtrips saved because of the batching requests optimisation natively available in Falcor APIs and the nice asynchronous implementation to fetch data from the unique model.
I’ve to admit that I was really surprised and I believe sooner than later I’ll introduce Falcor.js in production because it can really simplify the pipeline of work and provide great benefits to your applications in particular when you are targeting different low end devices like in my project.
Another think that would be good to invest time on(maybe another weekend :P) is GraphQL, the main “competitor”, maybe I’ll be able to do a 1 to 1 comparison based on the same problem and see which is the best library for a specific problem.
Meanwhile if you want to start playing with it I recommend Falcor website and I encourage you to keep an eye on this blog because I’d like to share in another post more technical information about Falcor that will allow you to understand how easy is working with it.