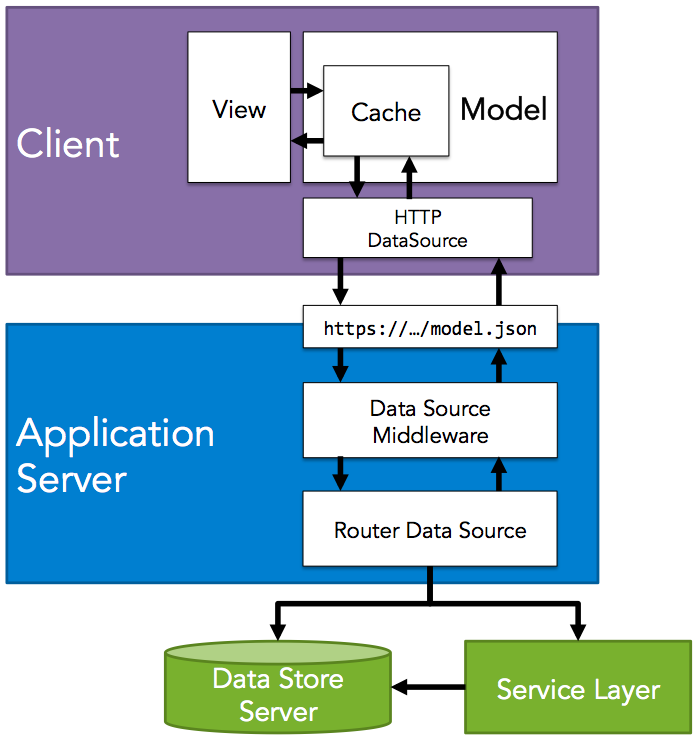
Are you frustrated with slow deployment cycles, tightly coupled dependencies, and the cumbersome nature of managing monolithic front-end codebases? These common issues plague many development teams, leading to decreased productivity and delayed project delivery. Enter micro-frontends, an approach designed to tackle these challenges head-on.
But what exactly are micro-frontends, and why do they matter?
Why Micro-Frontends Matter
Micro-frontends break down monolithic front-end codebases into smaller, more manageable pieces. Each piece, or micro-frontend, can be developed, tested, and deployed independently. This modular approach offers agility and speed, transforming the way you approach front-end development.
Defining Micro-Frontends
Micro-frontends extend the principles of microservices to the front-end, allowing teams to build and deploy individual artifacts independently. This approach is particularly beneficial for organizations with a microservices architecture, as it aligns with similar principles and goals.
Unlike traditional components, micro-frontends are optimized for independent deployment and scalability. While they are not specifically designed for multi-framework approaches, they excel in environments where decoupling and modularization are paramount.
I highly recommend watching this 10 mins video where I describe the difference between micro-frontends and components:
Practical Applications of Micro-Frontends
Micro-frontends can be applied to various types of websites and applications. In the past years I followed over 100 teams worldwide.
From E-commerce Sites with server-side rendering to B2B Platforms with client-side rendering but also video streaming services, financial services, insurance websites, entertainment or travel websites and more.
Nowadays there are many companies who publicly shared they have implemented micro-frontends for their applications. A few names are: booking.com , Netflix, PayPal, DAZN, Lululemon, Dunelm, Postman, BMW, Adidas, BestBuy, Epic Games, Shopify, Business Insider and many many others.
Choosing the Right Split
Deciding between horizontal and vertical splits depends on several factors, including team size, reusability, and simplicity. Bear in mind that a micro-frontends architecture enables you to use the right split for the domain you identify inside your system. So don’t be afraid to use vertical or horizontal split interchangeably.
Horizontal Splitting: A Slice of the Page
Horizontal splitting allows multiple micro-frontends to coexist on a single page, with different teams potentially owning different sections. While this method offers flexibility, it also presents some challenges:
- Cohesive Design: Teams need to define a the right governance to make this happen. For instance, set up Dependabot for enforcing the design system library version.
- Coordination Overhead: With multiple teams contributing to the same page, effective communication and coordination become essential — and sometimes time-consuming. Therefore identifying a single team responsible to the finally result of the view is a good option I’ve seen implemented in several organisations.
- Domain Disconnect: This approach may stray from the principle of modeling around business domains, which can lead to create several distributed components instead of micro-frontends. Keep an eye on the friction and start more coarse grain than move to fine grain split eventually.
Vertical Splitting: One Domain, One Micro-Frontend
In vertical splitting, each micro-frontend represents a complete business domain. This approach has several advantages:
- Promotes Domain Expertise: Teams can dive deep into their specific business areas, becoming true experts.
- Enhances Autonomy: Teams enjoy greater independence, allowing them to make decisions that best serve their domain.
- Aligns with Traditional Approaches: This method aligns more closely with single-page application (SPA) or server-side rendering methodologies.
- Reduces Fragmentation: The implementation remains cohesive within each domain, leading to a more streamlined development process.
Which Approach Should You Choose?
The decision between horizontal and vertical splitting ultimately depends on your organization’s structure, the nature of your application, and your team’s objectives.
Vertical splitting tends to align better with the principle of modeling around business domains. This approach can lead to more scalable organizations and foster effective, autonomous teams. By establishing clearer ownership and responsibility, you may find that the quality of development improves as well.
On the other hand, horizontal splitting might be suitable for scenarios where extreme flexibility in page composition is required, or when dealing with legacy systems that are challenging to separate completely. It’s definitely more complicated to implement but when it’s done properly it provides more flexibility to evolve a system properly.
To truly understand these approaches and see them in action, don’t miss the exclusive video I’ve created.
In it, I break down the concepts with real-world examples, showing you exactly how to split micro-frontends effectively.
Structuring Teams for Success
Effective implementation of micro-frontends requires thoughtful and strategic team organization. Typically, a core or platform team is responsible for overseeing the overall architecture and governance of the project. This team ensures that best practices are followed, standards are maintained, and that the overall vision of the application is adhered to. Meanwhile, individual teams can focus on specific micro-frontends, dedicating their efforts and expertise to developing and enhancing those particular areas. This structure not only promotes collaboration among various teams but also ensures consistency and uniformity across the entire application. By having a clear division of responsibilities and a well-defined governance process, organizations can achieve a more seamless and efficient development process.
I delivered a keynote about the Perfect micro-frontends platform for the micro-frontends conference. You can find the recording here:
ontinuous Learning and Improvement
Micro-frontends are not a one-size-fits-all solution. They are a powerful tool that, when used correctly, can revolutionize your development process. Continuous reassessment and refinement of your governance approach are essential to accommodate the evolving nature of your system.
For example, consider an e-commerce platform that initially adopted a monolithic front-end approach. Over time, as the platform grew, deployment cycles became cumbersome, and managing dependencies became a nightmare. By transitioning to micro-frontends, the platform was able to break down its codebase into smaller, more manageable units. Each team could now focus on specific parts of the application, such as the product catalog, checkout process, and user reviews. This modularity allowed for faster deployment cycles, easier maintenance, and greater flexibility in adopting new technologies.
Another example can be seen in a large media streaming service. Initially built as a monolithic application, the service faced challenges in scaling and deploying updates quickly. By adopting micro-frontends, the team divided the application into distinct domains, such as the landing page, user authentication, and content streaming. This vertical split enabled each team to work independently on their respective domains, leading to quicker feature releases and a more responsive user experience.
These examples highlight the importance of continuously reassessing and refining your governance approach to accommodate the evolving nature of your system. By doing so, you can ensure that your micro-frontends remain effective, scalable, and aligned with your organization’s goals.
Summary
In conclusion, micro-frontends offer a powerful solution to the challenges posed by monolithic front-end applications. By adopting this approach, you’ll unlock faster deployments, streamlined code management, and more efficient teams. It’s not just a one-time change — it’s an ongoing journey of learning and refinement. I encourage you to join me on this exciting path of continuous improvement.
If you are interested to know more and discover how the community is evolving, I encourage to subscribe to the micro-frontends newsletter, a fortnightly newsletter that will gather for you content on this topic completely for FREE: https://www.buildingmicrofrontends.com/