When I tried for the first time Visual Studio Code on my Mac I remained quite impressed about its performances.
The investment Microsoft did during the last few years on this editor is really remarkable, considering also that it’s an open source software and not a commercial one.
As you know with Visual Studio Code you can create your own extensions and then share with the community inside the marketplace.
This for me was just an interesting and quick pet project before going back the my reactive studies, but it is worth to share it
I created a simple extensions for retrieving all the annotations in my Javascript projects grouping per categories inside the output panel or in a markdown file.

You can download the extension called vscode-annotations directly from the marketplace or inside the extensions panel in Visual Studio Code editor.
If you want instead take a look to the source, feel free to clone the project from Github.

First steps
If you wanna quickly start working on an extension, there is a Yeoman generator provided by the Visual Studio Code team that will create the folder structure and the necessary files for publishing your extension later on.
In order to use it just run these commands in your terminal window:
npm install -g yo generator-code yo code
During the generation, the interactive generator will ask if you prefer working with Typescript or pure Javascript, in my case I picked the latter one.
After that you will have your project ready and you can start to have fun with Visual Studio Code!
if you prefer start with the classic Hello World project feel free to check Microsoft tutorial.
In my annotations extension what I’ve done is just providing 3 commands available in the command palette (CMD+SHIFT+P or View > Command Palette) :
. output all the annotations in the file opened inside the editor
. output all the annotations in a specific project
. export all the annotations in a specific project to a Markdown file
The first two will create an output panel inside the editor showing the annotations present inside a specific file or an entire workspace, the third one will create a markdown file with all the annotations for a specific project.
When you want to create a command inside the command palette, you need to set it up in few files, the first one is the package.json:
"activationEvents": [ "onCommand:extension.getAnnotations", "onCommand:extension.getAllAnnotations", "onCommand:extension.createAnnotationsOutput" ]
and then in the commands array:
"contributes": {
"commands": [
{
"command": "extension.getAnnotations",
"title": "ANNOTATIONS: check current file"
},
{
"command": "extension.createAnnotationsOutput",
"title": "ANNOTATIONS: export markdown file"
},
{
"command": "extension.getAllAnnotations",
"title": "ANNOTATIONS: check current project"
}]
}
so in the commands array we are just defining the label that will be inside the command palette and the action that should be triggered when the user selects a specific command.
Then we will need to add each of them in the extension.js file (created by the scaffolder) inside the activate method that will be triggered once the editor will have loaded your extension:
vscode.commands.registerCommand('extension.getAnnotations', function () {
// extension code here
});
Just with these few lines of code you can see the expected results of having your commands present in the palette

Microsoft is providing a well documented APIs for interacting with the editor, obviously, because it’s based on Electron bear in mind that you can also use Node.js APIs for extending the functionalities of your extension, for instance to create a file or interacting with the operating system.
Working with the workspace
When you want to interact with the editor manipulating files or printing inside the embedded console you need to deal with the workspace APIs.
In order to do that you need to become confident with a couple of objects of the vscode library:
- window
- workspace
With window and workspace you can handle end to end the editor UI and the project selected.
Window object is mainly use to understand what’s happening inside a file meanwhile an user is editing it.
You can also use the window object for showing notification or error messages or change the status bar
With the workspace object instead, you will be able to manage all the interactions that are happening inside the menu or editor interface.
Workspace object is useful when you want to iterate trough the project files or if you need to understand which files are currently open in the editor and when they will be closed for instance.
In my extension I used these 2 objects for showing a notification to the user:
vscode.window.showErrorMessage('There aren\'t javascript files in the open project!');
for interacting with the output panel:
vscode.window.createOutputChannel(outputWin_NAME);
[....]
outputWin.appendLine(`FILE -> file://${doc.fileName}`);
outputWin.appendLine("-----------------------------------------");
outputWin.appendLine(getBody(data, OUTPUT_PANEL_CONFIG))
outputWin.appendLine(OUTPUT_PANEL_CONFIG.newline);
outputWin.show(true);
and for iterating and opening a javascript file present inside a proejct:
vscode.workspace.openTextDocument(file.path)
[...]
vscode.workspace.findFiles('**/*.js', '**/node_modules/**', 1000).then(onFilesRetrieved)
Debugging an extension
Considering you are developing an extension for an editor you can easily debug what you are doing simply running the extension debug mode (F5 or fn+F5 from your macbook).
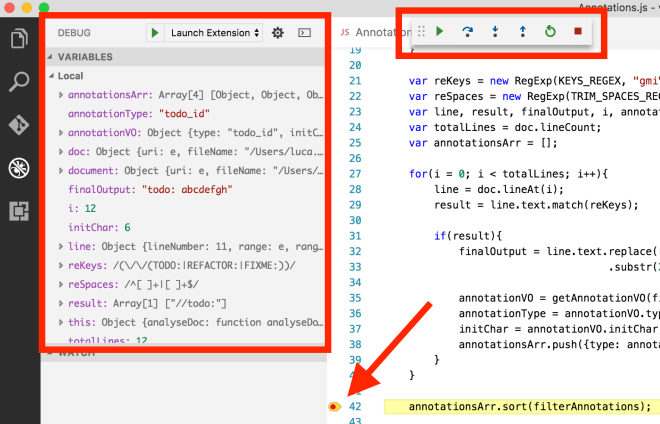
Few suggestions regarding the debug mode:
- console.dir doesn’t work, console.log will substitute what console.dir does if you are inspecting an object but not an array!
- when an error occurs it’s not very self-explained (kudos to Facebook for the react native errors handling, best implementation ever!) so you will need to follow the stack trace as usual
Publishing an extension
Last part of this brief post will be related to the submission of your extension to the Visual Studio Code marketplace.
Also in this case Microsoft did a good job creating an extensive guide on how to do that, few suggestions also in this case:
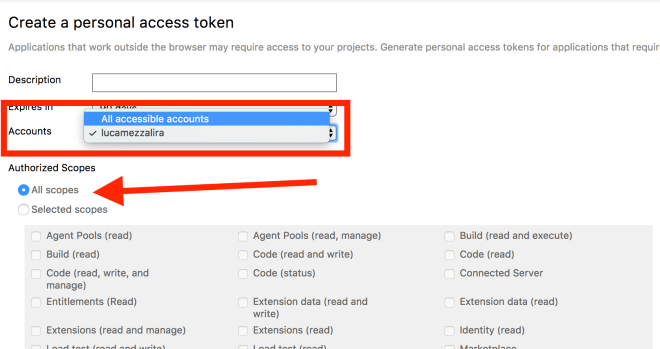
- in order to submit an extension in the marketplace you will need to create a Microsoft and a Visual Studio Team Service accounts
- when you create the Personal Access Token for publishing your extension, bear in mind to set access to all accounts and all scope otherwise you could end up with a 401 or 404 error when you try to publish the extension
- vsce command line tool is pretty good in order to create a publisher identity and super fast to publish an application on the marketplace.
Considering that is a CLI tool you can also automate few part of the publishing process (increasing release number for instance) adding a scripts in your package.json - to make your extension more accessible in the marketplace, remember to add the keywords array inside the package.json with meaningful words and the appropriate category, at the moment there are the following categories available:
DebuggersExtension PacksFormattersKeymapsLanguagesLintersSnippetsThemesOther

Wrap up
There could be tons of other things to do and to discover for developing a Visual Studio Code extension but I think that could be a good recap of the lessons learnt for creating one that you could use along with the Microsoft guide.